Model-Agnostic Meta-Learning(MAML)介绍与算法分析
1.Meta-Learning
1.1介绍
常见的深度学习模型,目的是学习一个用于预测的网络模型,比如能够实现猫狗分类的模型,我们学习训练的是模型的参数,学习的目的是让最终训练好的参数在数据集上的准确率越高,但 Meta Learning 面向是的学习的过程而非结果,如我们在学习英语时,若是模仿apple 的发音,我们能很快的学会说这个单词,但当我们碰到新的单词如 banana 时会无从下手,这就是我们学习音标的原因,学习音标的过程正是元学习的体现
(1)Meta Learning 中文翻译为“元学习”,它研究的不是如何提升模型解决某项具体的任务(分类,回归,检测)的能力,而是研究如何提升模型解决一系列任务的能力;Meta learning 即 learn to learn ,我们希望机器学习怎样去学习这件事情,就是学会语音辨识、图像辨识以后,它学会了如何去学习学习这件事情,而不是停留在语音和图像的任务上
(2)我们希望通过 meta-learning 学习出一个非常好的模型初始化参数,有了这个初始化参数后,我们只需要少量的样本就可以快速在这个模型中进行收敛
meta-learning 在 few-shot 中经常使用,因为 meta learning 的训练任务很多,因此每个任务的样本很少
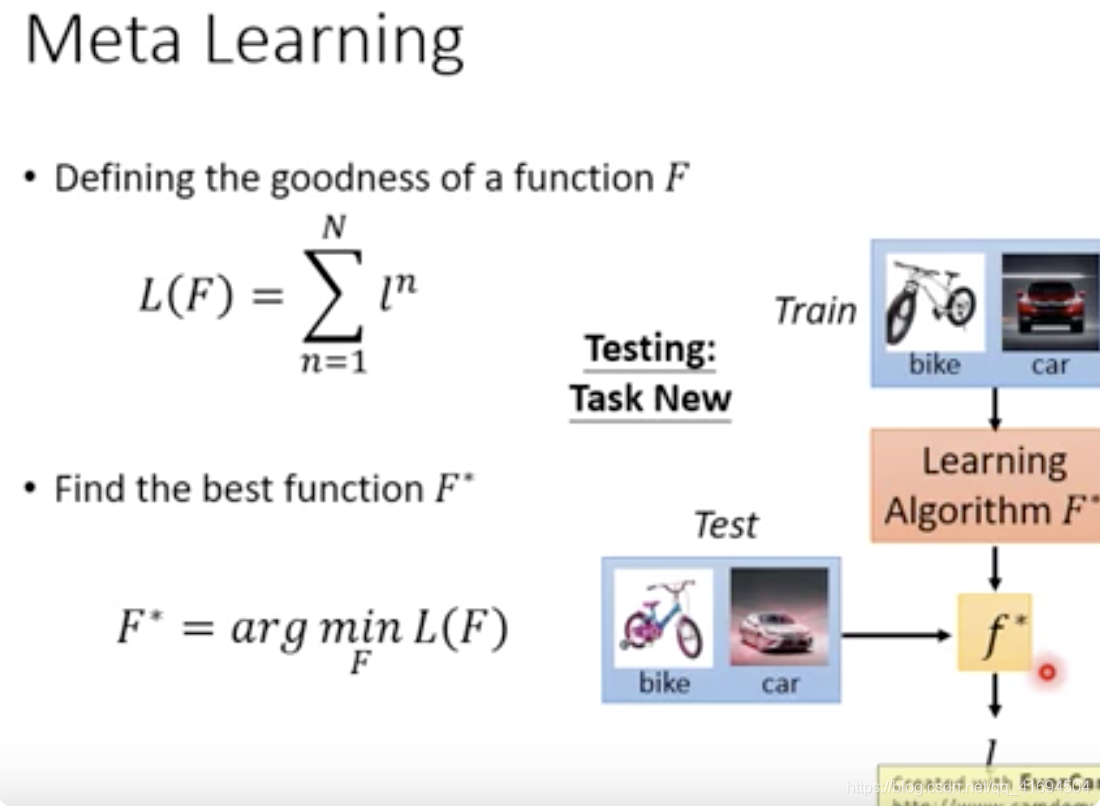
(3)在 meta-learning 中,把学习算法也当作一个函数 F ,吃进去的是训练资料,吐出来另外一个function,要找一个函数 F,输入是训练资料输出是模型
| 目的 | 输入 | 函数 | 输出 | |
|---|---|---|---|---|
| 机器学习 | 通过训练数据学习输入X与输出Y之间的映射,找到函数f | X | f | Y |
| 元学习 | 通过task找到函数F,F可以输出一个函数f,f用于新的任务 | task | F | f |
1.2训练
-
首先定义 F 的损失函数(N 表示 N 个 task ,ln 表示第 n 个 task 的损失) $$ L(F)=\sum_{n=1}^{N}l^{n} $$
-
找一个最好的 F* 使 Loss 最小,得到学习算法 F*
-
测试时我们首先用 testing set 的 support set 去让 F* 找出 f* ,然后使用 f* 来对 testing set 的 query set 进行测试
1.3相关概念
1.3.1 N-way K-shot
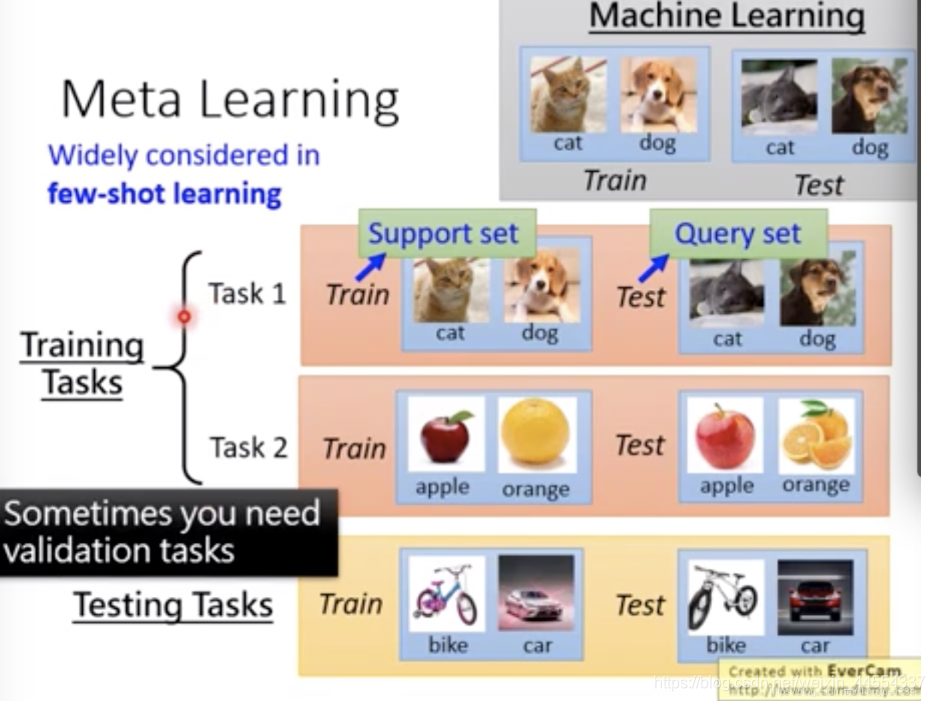
在 few-shot learning 中有一个术语叫做 N-way K-shot 问题,简单的说就是我们需要分类的样本属于 N 个类中一种,但是我们每个类训练集中的样本只有 K 个,即一共只有 N ∗ K 个样本的类别是已知的
1.3.2 task
既然是学会学习,那么输入就不是简简单单的数据了,而是一组一组的 task ,比如猫狗分类、水果分类等等都是一个个 task ,那么这些 task 应该如何分类呢?
在 machine learning 中,准备训练集和测试集,在 meta learning 中,准备训练任务及其对应的资料
- 在训练中将 task 划分为
training tasks和testing tasks - 在few-shot中,通常把上述的 tasks 中的 train 和 test 称为
support set和query set。
1.3.3 Model-Agnostic
Model-Agnostic 即模型无关,这里的模型无关意思是 MAML 可以用于 CNN RNN 甚至 RL 中,绝大多数深度学习模型都可以作为 base-learner 无缝嵌入MAML中
2.MAML
2.1基本思想
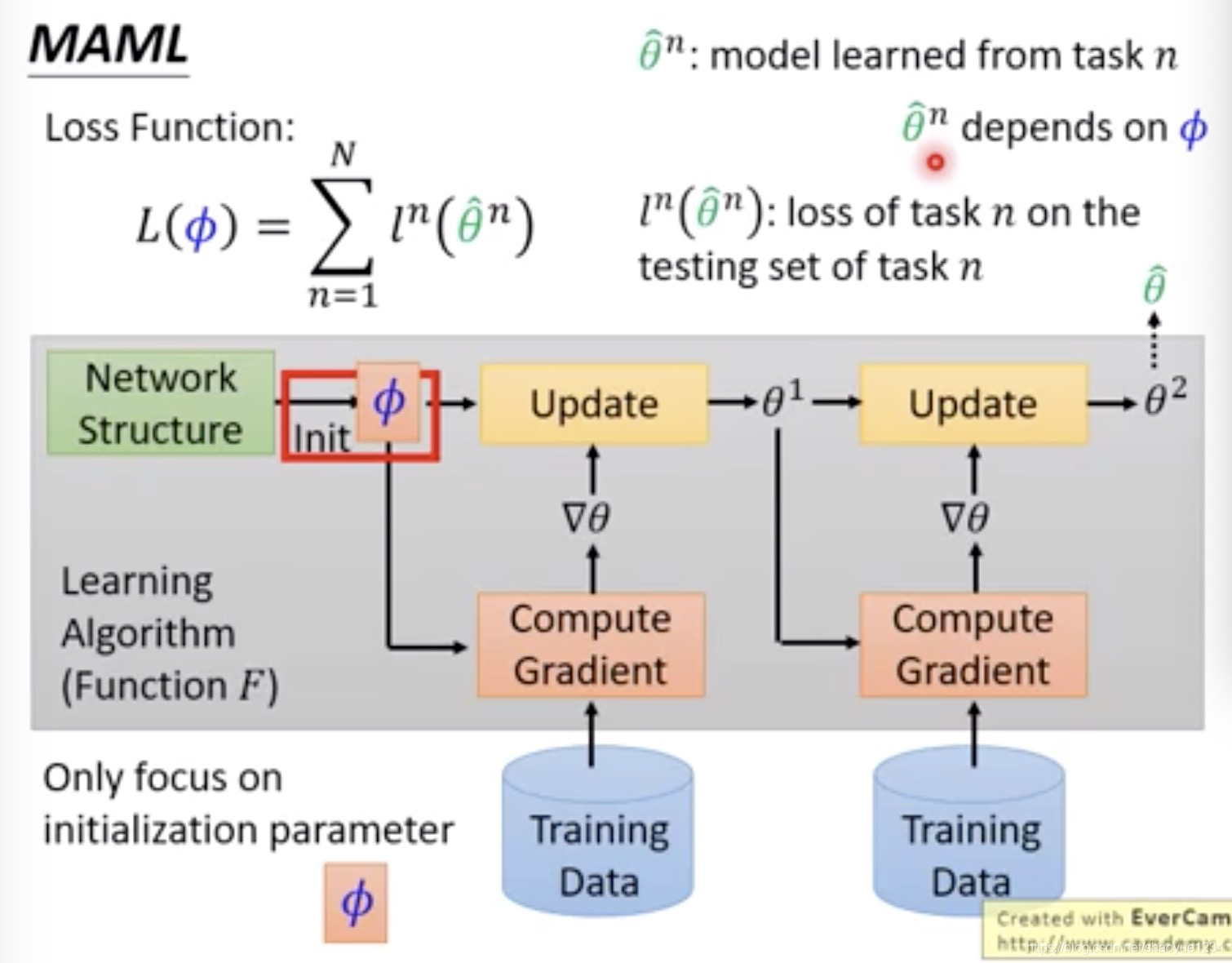
(1)目的:学 MAML 的思想是学习一套初始化参数 ,这个初始化参数在遇到新的问题时,只需要使用少量的样本 (few-shot learning) 进行几步梯度下降就可以取得很好地效果
(2)方法:定义损失函数,提供一套初始化参数,然后让网络在不同 task 上去训练,最终得到属于不同task的网络参数,然后评估这些不同的网络参数在各自 task 上的测试集里表现如何,得知最初的这套初始化参数到底怎么样
2.2MAML与model Pre-training
model pre-training 和 MAML 的区别是损失是不同的。
- MAML找一组初始化参数经过训练得到好的结果(潜力)
- model pre-training 找一组初始化参数在所有的task上得到好的效果(现在表现的效果)

2.3算法流程
MAML中是存在两种梯度下降的,也就是gradient by gradient。第一种梯度下降是每个task都会执行的,而第二种梯度下降只有等batch size个task全部完成第一种梯度下降后才会执行的

以 5-way 5-shot 例子为例,算法流程如下
- MAML在 task 上进行训练,training tasks 分为若干个 task ,每个 task 又区分了 support set 和 query set
- 我们用于训练的模型架构是
 (初始化参数为),假设是一个输出节点为 5 的CNN,训练的目的是为了使得模型有较优秀的初始化参数
(初始化参数为),假设是一个输出节点为 5 的CNN,训练的目的是为了使得模型有较优秀的初始化参数 - 我们将1个任务task的support set去训练 ,这里进行第一种梯度下降,也就是 。在执行第2个task训练时,有 。执行第 batch size 个 task 后,有
- 上述步骤3用了 batch size 个 task 对 进行了训练,然后我们使用上述batch个task中地query set去测试参数为,获得总损失函数 ,这个损失函数就是一个batch task中每个task的query set的损失函数之和
- 获得总损失函数后,我们就要对其进行第二种的梯度下降。即更新初始化参数 ,也就是 来更新初始化参数。这样不断地从步骤3开始训练,最终能够在数据集上获得该模型比较好的初始化参数(若无法对进行学习,使用强化学习训练)
关于以上过程补充以下解释:假设原模型为
参考资料
[1] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
[2] Model-Agnostic Meta-Learning (MAML)模型介绍及算法详解